
As part of the engineering workflow — writing, editing, testing, and shipping code — we rely on backend services and machines to do a variety of jobs, such as building new packages, installing dependencies, and running tests. At Facebook’s scale, the number and variety of jobs engineers need to execute every day can build up and become a bottleneck in the system. Our goal is to minimize the amount of time engineers spend waiting on machines so that they can get feedback quickly and spend more time on productive tasks.
Every job runs in an isolated environment called a worker, and these are distributed across different hosts in different data centers. Workers are pre-configured to run certain types of jobs – for example, an Android job coming in will go to a worker that has the right codebase and dependencies already updated.
This type of distributed system needs some mechanism to deliver jobs to the appropriate workers reliably and efficiently. Common solutions range from distributed queues to scheduler/dispatcher systems that track the current state of the world and attempt to optimally distribute the workload. However, these solutions come with trade-offs; e.g., schedulers tend to become a scalability bottleneck. In this post we describe Jupiter, a service we built with one aspect in mind: capabilities matching.
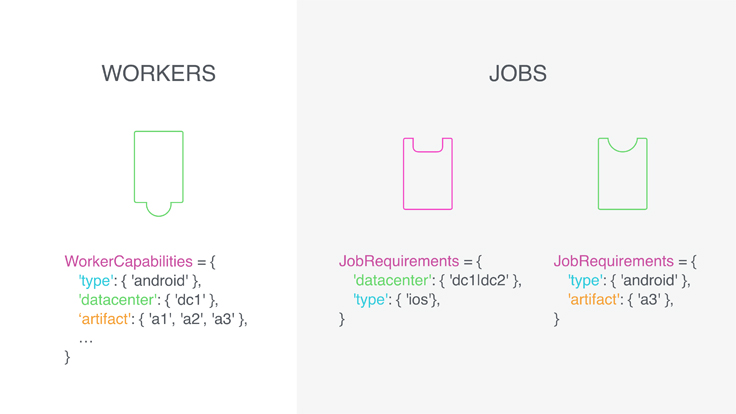
For workers, a capability is essentially a declaration of a worker’s traits or what it can do. Examples are hardware resources like RAM size, which data center the worker is in, the current load factor of the machine, models of smartphones the worker is connected to, repositories or data artifacts pre-loaded onto the machine, and so on. Each worker has multiple capabilities, and each capability is a set of one or more values (e.g. RAM size is a singular value, but there could be several pre-loaded source code repositories.) Similarly, each job encodes the capabilities it requires. For instance, a resource-intensive build needs a beefy machine; a CI job for a diff in a certain repository is better picked up by a worker with the source code already pre-loaded; a job that needs a given kernel version can be executed only by a worker running on that kernel; a group of distributed builds is best executed in a certain cluster.
The task of matching multidimensional capabilities in the presence of a constant stream of updates and concurrent requests is a fascinating engineering problem. Jupiter is a service that excels at efficiently responding to requests for work from a pool of workers and keeping track of currently available jobs in a system where both workers and jobs can have multidimensional capability constraints. Jupiter guarantees atomic job acquisition — a job will be given to only one worker even if multiple requests are in flight, and once a worker acknowledges receipt of the job, it cannot be given to anyone else.
Like many other Facebook backend services, Jupiter is written in C++ and accessible via Thrift. It is horizontally scalable — it can be sharded easily, where each of the shards makes independent decisions about its slice of the job set, and there is no single leader node responsible for everything. Jupiter respects the order in which jobs are enqueued. Ordering policies within a shard can be as simple as first-in, first-out, but other concepts like job priorities are supported as well. Performance-wise, it’s able to handle hundreds of thousands of requests per second per shard.
Workers send requests to Jupiter advertising all the capabilities they have, and Jupiter finds the best match by consulting its internal data structures. On production workloads, the latency of work acquisition requests is on the order of tens of microseconds. Upon receipt of a job, the worker either acknowledges or rejects it by sending an appropriate request back to Jupiter. In the case of a rejection, the job is placed into a staging area for a period specified in the request; it can’t be given to another worker during this time. Different flavors of the acknowledgment APIs are available. For example, a worker can send a lease request to Jupiter indicating that it’s started processing the job but intends to acknowledge it only upon successful completion. At a high level, all Jupiter clients follow the pattern of acquiring a job, acknowledging it, working on it, and returning to the start of the cycle.
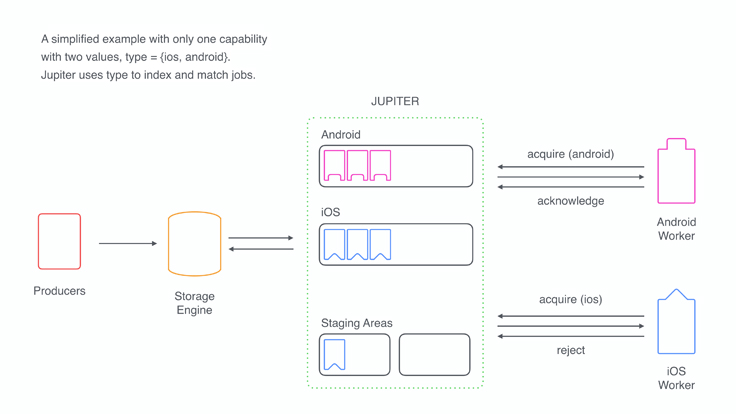
Because Jupiter possesses the knowledge of all jobs in the queue, it can make high-level scheduling decisions like allowing a job to be given to workers only after certain other prerequisite jobs have completed. For many use cases, the main benefit of Jupiter is simply the ability to efficiently consume jobs by a pool of (heterogeneous) workers, along with the reliability and atomicity that it provides. At Facebook, Jupiter supports different customers like One World, our resource management system, and our continuous integration system, Sandcastle. API boundaries between data and matching modules are clean, so integrating with new systems is very easy.
It’s important to mention what Jupiter explicitly is not. It’s not a data persistence layer. If job data needs to be recorded, the producer side is responsible for that, and Jupiter constantly fetches delta updates from the persistence layer and keeps an up-to-date view of the world. The rationale here is twofold. First, we believe services should specialize in a few things instead of being responsible for everything. Second, by decoupling job storage and job matching, we ensure that Jupiter is not a single point of failure of the whole system: If Jupiter goes down, job producers are still able to enqueue jobs, and once Jupiter is back up, all of the enqueued jobs are delivered to workers intact. Jupiter abstracts away all stateful operations behind a data provider interface, and implementations are free to use any storage engine of their choosing — be it a relational database, a distributed filesystem or, in cases where persistency is not required, Jupiter’s own in-memory storage.
Jupiter also does not possess global knowledge about the state of the workers (e.g., which workers are busy at the moment or who is capable of processing a given job) and does not make any centralized decisions about what jobs should be sent where. Instead, jobs are distributed efficiently because workers request only the kinds of jobs they specialize at; jobs themselves encode what traits a potential worker needs to have; and Jupiter acts as an efficient arbiter that gives available jobs to workers best suited to handle them.
In summary, Jupiter is an efficient job-matching service well suited for producer/consumer types of distributed systems. Its features are made possible by keeping the global jobs state in a dedicated service, and its versatile capabilities can be used by other systems. We hope our experience and findings will benefit the broader engineering community.










